1 Bret Victor
-
http://worrydream.com/MediaForThinkingTheUnthinkable/note.html
-
http://worrydream.com/TheHumaneRepresentationOfThought/note.html
2 Alan Kay
https://www.youtube.com/watch?v=YyIQKBzIuBY, HPI
3 Design of electronic books
Reading and Writing the Electronic Book Marshall (2009) ¶
Designing for Digital Reading Pearson et al. (2013) ¶
4 Software engineering
Dreaming in code: two dozen programmers, three years, 4,732 bugs, and one quest for transcendent software Rosenberg (2008) ¶
5 Workflow
In The cognitive basis for academic workflows, Lisa D. Harper looks at sensemaking models as a way to understand academic workflows.
6 Scene graphs
Handling Massive Transform Updates in a Scenegraph Tavenrath (2016) ¶
-
dynamic scene graph: many updates
-
extract just transform nodes to a transform tree
The world matrix is used for shader, culling, bounding box, collision detection.
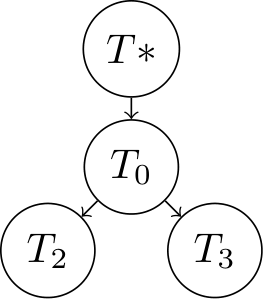
Lazy incremental computation for efficient scene graph rendering Wörister et al. (2013) ¶
-
scene graph creates dependency graph
-
program updates scene graph updates dependency graph
but only parts that are visible are updated
Incremental context-dependent analysis for language-based editors Reps et al. (1983) ¶
Incremental attribute evaluation: A flexible algorithm for lazy update Hudson (1991) ¶
They use a semantic scene graph as in Separating semantics from rendering: a scene graph based architecture for graphics applications Tobler (2011) — traversal cost is high — caching eliminates this cost.
caching however occurs an overhead (see Table 1 of paper) at startup time
need to benchmark the number of draw calls to see when it will pay off: draw calls, frame rate.
can be parallelised
Separating semantics from rendering: a scene graph based architecture for graphics applications Tobler (2011) ¶
semantic graph is used to keep application state inside of graph
application acts like a compiler
semantic scene graph rendering scene graph
a single semantic scene graph node can build many intermediate rendering scene graph nodes that differ based on rendering backend
applicator nodes are trees as well
transformation
-
children: transformation matrices
-
aggregator: matrix multiplication
LOD node: returns a different scene graph based on level
multiple-view has both:
-
shared data
-
private data
for
-
traversal cache
-
traversal state
editing of semantic nodes
-
back references
-
a little unclear why have 2 rendering scene graphs
-
render normal
------ | | ------ -
edit handles
o o o o -
render w/ edit handles
o----o | | o----o
-
rendering scene graph is cached by creating scene graph forest
Scene-Graph-As-Bus: Collaboration between Heterogeneous Stand-alone 3-D Graphical Applications Zeleznik et al. (2000) ¶
networking
OpenSceneGraph
TODO
7 Attribute grammars
Attribute grammars were first introduced by Knuth. They consist of a normal grammar, but augmented with attributes. Attributes are the results of calculations based on the values and attributes of nodes in the parse tree. Knuth (1968).
One issue with attributes grammars is determining the order of evaluation. One naive approach is to use a topological sort based on the dependency graph of the attributes.
Example 7.1. Example: Attribute grammar for summing values in list. Taken from Steinlechner et al. (2019).
Data structure
interface List { } class Cons : List { Int Value; List Rest; } class Nil : List { }
Attribute grammar (UUAGC syntax)
syn SEM List | Nil this.Sum = 0 | Cons this.Sum = this.Value + this.Rest.Sum
In this example, the attribute grammar defines a synthesised attribute Sum. The order of evaluation is bottom-up and since this grammar only uses a synthesised attribute, it is an S-attributed grammar.
There are also special classes of attribute grammars than can be evaluated in a single pass during parsing despite having both synthesised attributes and inherited attributes.
For a synthesised attribute and production the semantic function for can depend on attributes from , , or .
For the inherited attribute on the same production, can depend on attributes from , , or (every other symbol).
However, to evaluate a general class of attribute grammars, a specific traversal would be needed for each attribute grammar depending on the dependencies for the semantic functions. There existed algorithms that can take a specific attribute grammar and compute a traversal function for an attribute. Some of these are implemented in the for of a code generating compiler (e.g., UUAGC, JastAdd). UUAGC which uses a version of the Kennedy and Warren (1976)) algorithm that is described in Bransen et al. (2012).
These algorithms are often used in an ahead of time compiler in order to generate a static tree-walker evaluator. However, in some applications, an online version may be useful for dynamic editing of values on the trees or changes to the tree structure itself (e.g., a language editor). This merges the work in attribute grammars with work in incremental computing Reps et al. (1983); Ramalingam and Reps (1993).
In order to use attribute grammars in a way that they can be composable (in FP, AGs can be used to define catamorphisms compositionally) and easy to write, there has been work on making embedded DSLs for AG definitions Sloane et al. (2010).
8 Incremental computing
9 Self-adjusting computation
References
Jeroen Bransen, Arie Middelkoop, Atze Dijkstra, and S Doaitse Swierstra. The
kennedy-warren algorithm revisited: ordering attribute grammars. In International
Symposium on Practical Aspects of Declarative Languages, pages 183–197.
Springer, 2012. doi: 10.1007/978-3-642-27694-1
Abstract: Attribute Grammars (AGs) are a powerful tool for defining an executable semantics of a programming language, and thus for implementing a compiler. An execution plan for an AG determines a static evaluation order for the attributes which are defined as part of an AG specification. In building the Utrecht Haskell Compiler (UHC), a large scale AG project, we discovered that the Ordered AG approach (Kastens, 1980) for building such plans becomes impractical: the additional dependencies between attributes introduced by this algorithm too often result in grammars for which no execution plan can be generated. To avoid such problems we have implemented a refined version of the algorithm of Kennedy and Warren (1976) as part of our purely functional AG system and show how this algorithm solves the problems that surface with the Ordered AG approach. Furthermore, we present the results of applying this algorithm to the UHC code and show that this approach in some cases also has a positive effect on the runtime of the resulting program.
URL http://dx.doi.org/10.1007/978-3-642-27694-1_14.
Scott E Hudson. Incremental attribute evaluation: A flexible algorithm for lazy update. ACM Transactions on Programming Languages and Systems (TOPLAS), 13(3):315–341, 1991. doi: 10.1145/117009.117012.
Abstract: This paper introduces a new algorithm for incremental attribute evaluation. The algorithm is lazy: It evaluates only the attributes that are both affected by a change and that are directly or indirectly observable by the user. In this way, the wasted work of computing values that are never actually used is avoided. Although the algorithm is not optimal, it performs better than the standard “optimal” algorithm in cases where expensive but optional computations need to be supported. Furthermore, the algorithm does not have some of the limitations of other algorithms. It works for general attributed graphs as well as for standard attributed trees. In addition, it does not presume any special editing model, and it supports multiple change points without loss of efficiency.
URL http://dx.doi.org/10.1145/117009.117012.
Ken Kennedy and Scott K Warren. Automatic generation of efficient evaluators for attribute grammars. In Proceedings of the 3rd ACM SIGACT-SIGPLAN symposium on Principles on programming languages, pages 32–49. ACM, 1976. doi: 10.1145/800168.811538.
Abstract: The translation process may be divided into a syntactic phase and a semantic phase. Context-free grammars can be used to describe the set of syntactically correct source texts in a formal yet intuitively appealing way, and many techniques are now known for automatically constructing parsers from given CF grammars. Knuth’s attribute grammars offer the prospect of similarly automating the implementation of the semantic phase. An attribute grammar is an ordinary CF grammar extended to specify the “meaning” of each string in the language. Each grammar symbol has an associated set of “attributes:”, and each production rule is provided with corresponding semantic rules expressing the relationships between the attributes of symbols in the production. To find the meaning of a string, first we find its parse tree and then we determine the values of all the attributes of symbols in the tree.
URL http://dx.doi.org/10.1145/800168.811538.
Donald E Knuth. Semantics of context-free languages. Mathematical systems theory, 2(2):127–145, 1968. doi: 10.1007/bf01692511.
Abstract: “Meaning” may be assigned to a string in a context-free language by defining “attributes” of the symbols in a derivation tree for that string. The attributes can be defined by functions associated with each production in the grammar. This paper examines the implications of this process when some of the attributes are “synthesized”, i.e., defined solely in terms of attributes of the descendants of the corresponding nonterminal symbol, while other attributes are “inherited”, i.e., defined in terms of attributes of the ancestors of the nonterminal symbol. An algorithm is given which detects when such semantic rules could possibly lead to circular definition of some attributes. An example is given of a simple programming language defined with both inherited and synthesized attributes, and the method of definition is compared to other techniques for formal specification of semantics which have appeared in the literature.
URL http://dx.doi.org/10.1007/bf01692511.
Catherine C. Marshall. Reading and Writing the Electronic Book, volume 1. Morgan & Claypool Publishers, 2009. doi: 10.2200/S00215ED1V01Y200907ICR009.
Abstract: Developments over the last twenty years have fueled considerable speculation about the future of the book and of reading itself. This book begins with a gloss over the history of electronic books, including the social and technical forces that have shaped their development. The focus then shifts to reading and how we interact with what we read: basic issues such as legibility, annotation, and navigation are examined as aspects of reading that ebooks inherit from their print legacy. Because reading is fundamentally communicative, I also take a closer look at the sociality of reading: how we read in a group and how we share what we read. Studies of reading and ebook use are integrated throughout the book, but Chapter 5 “goes meta” to explore how a researcher might go about designing his or her own reading-related studies. No book about ebooks is complete without an explicit discussion of content preparation, i.e., how the electronic book is written. Hence, Chapter 6 delves into the underlying representation of ebooks and efforts to create and apply markup standards to them. This chapter also examines how print genres have made the journey to digital and how some emerging digital genres might be realized as ebooks. Finally, Chapter 7 discusses some beyond-the-book functionality: how can ebook platforms be transformed into portable personal libraries? In the end, my hope is that by the time the reader reaches the end of this book, he or she will feel equipped to perform the next set of studies, write the next set of articles, invent new ebook functionality, or simply engage in a heated argument with the stranger in seat 17C about the future of reading. Table of Contents: Preface / Figure Credits / Introduction / Reading / Interaction / Reading as a Social Activity / Studying Reading / Beyond the Book / References / Author Biography
URL http://dx.doi.org/10.2200/S00215ED1V01Y200907ICR009.
Jennifer Pearson, George Buchanan, and Harold Thimbleby. Designing for Digital Reading, volume 5. Morgan & Claypool Publishers, 2013. doi: 10.2200/S00539ED1V01Y201310ICR029.
Abstract: Reading is a complex human activity that has evolved, and co-evolved, with technology over thousands of years. Mass printing in the fifteenth century firmly established what we know as the modern book, with its physical format of covers and paper pages, and now-standard features such as page numbers, footnotes, and diagrams. Today, electronic documents are enabling paperless reading supported by eReading technologies such as Kindles and Nooks, yet a high proportion of users still opt to print on paper before reading. This persistent habit of “printing to read” is one sign of the shortcomings of digital documents – although the popularity of eReaders is one sign of the shortcomings of paper. How do we get the best of both worlds? The physical properties of paper (for example, it is light, thin, and flexible) contribute to the ease with which physical documents are manipulated; but these properties have a completely different set of affordances to their digital equivalents. Paper can be folded, ripped, or scribbled on almost subconsciously – activities that require significant cognitive attention in their digital form, if they are even possible. The nearly subliminal interaction that comes from years of learned behavior with paper has been described as lightweight interaction, which is achieved when a person actively reads an article in a way that is so easy and unselfconscious that they are not apt to remember their actions later. Reading is now in a period of rapid change, and digital text is fast becoming the predominant mode of reading. As a society, we are merely at the start of the journey of designing truly effective tools for handling digital text. This book investigates the advantages of paper, how the affordances of paper can be realized in digital form, and what forms best support lightweight interaction for active reading. To understand how to design for the future, we review the ways reading technology and reader behavior have both changed and remained constant over hundreds of years. We explore the reasoning behind reader behavior and introduce and evaluate several user interface designs that implement these lightweight properties familiar from our everyday use of paper. We start by looking back, reviewing the development of reading technology and the progress of research on reading over many years. Drawing key concepts from this review, we move forward to develop and test methods for creating new and more effective interactions for supporting digital reading. Finally, we lay down a set of lightweight attributes which can be used as evidence-based guidelines to improve the usability of future digital reading technologies. By the end of this book, then, we hope you will be equipped to critique the present state of digital reading, and to better design and evaluate new interaction styles and technologies. Table of Contents: Preface / Acknowledgments / Figure Credits / Introduction / Reading Through the Ages / Key Concepts / Lightweight Interactions / Improving Digital Reading / Bibliography / Authors’ Biographies
URL http://dx.doi.org/10.2200/S00539ED1V01Y201310ICR029.
Ganesan Ramalingam and Thomas Reps. A categorized bibliography on incremental computation. In Proceedings of the 20th ACM SIGPLAN-SIGACT symposium on Principles of programming languages, pages 502–510. ACM, 1993. doi: 10.1145/158511.158710. URL http://dx.doi.org/10.1145/158511.158710.
Thomas Reps, Tim Teitelbaum, and Alan Demers. Incremental context-dependent analysis for language-based editors. ACM Transactions on Programming Languages and Systems (TOPLAS), 5(3):449–477, 1983. doi: 10.1145/2166.357218.
Abstract: Knowledge of a programming language’s grammar allows language-based editors to enforce syntactic correctness at all times during development by restricting editing operations to legitimate modifications of the program’s context-free derivation tree; however, not all language constraints can be enforced in this way because not all features can be described by the context-free formalism. Attribute grammars permit context-dependent language features to be expressed in a modular, declarative fashion and thus are a good basis for specifying language-based editors. Such editors represent programs as attributed trees, Which are modified by operations such as subtree pruning and grafting. Incremental analysis is performed by updating attribute values after every modification. This paper discusses how updating can be carried out and presents several algorithms for the task, including one that is asymptotically optimal in time.
URL http://dx.doi.org/10.1145/2166.357218.
Scott Rosenberg. Dreaming in code: two dozen programmers, three years, 4,732 bugs, and one quest for transcendent software. Three Rivers Press (CA), 2008. ISBN 978-1-400-08246-9.
Abstract: Our civilization runs on software. Yet the art of creating it continues to be a dark mystery, even to the experts. To find out why it’s so hard to bend computers to our will, Scott Rosenberg spent three years following a team of maverick software developers—led by Lotus 1-2-3 creator Mitch Kapor—designing a novel personal information manager meant to challenge market leader Microsoft Outlook. Their story takes us through a maze of abrupt dead ends and exhilarating breakthroughs as they wrestle not only with the abstraction of code, but with the unpredictability of human behavior—especially their own.
URL http://www.dreamingincode.com/.
Anthony M Sloane, Lennart CL Kats, and Eelco Visser. A pure object-oriented embedding of attribute grammars. Electronic Notes in Theoretical Computer Science, 253(7):205–219, 2010. doi: 10.1016/j.entcs.2010.08.043.
Abstract: Attribute grammars are a powerful specification paradigm for many language processing tasks, particularly semantic analysis of programming languages. Recent attribute grammar systems use dynamic scheduling algorithms to evaluate attributes by need. In this paper, we show how to remove the need for a generator, by embedding a dynamic approach in a modern, object-oriented programming language to implement a small, lightweight attribute grammar library. The Kiama attribution library has similar features to current generators, including cached, uncached, circular, higher-order and parameterised attributes, and implements new techniques for dynamic extension and variation of attribute equations. We use the Scala programming language because of its combination of object-oriented and functional features, support for domain-specific notations and emphasis on scalability. Unlike generators with specialised notation, Kiama attribute grammars use standard Scala notations such as pattern-matching functions for equations and mixins for composition. A performance analysis shows that our approach is practical for realistic language processing.
URL http://dx.doi.org/10.1016/j.entcs.2010.08.043.
Harald Steinlechner, Georg Haaser, Stefan Maierhofer, and Robert Tobler. Attribute grammars for incremental scene graph rendering. pages 77–88. SCITEPRESS - Science and Technology Publications, 02 2019. ISBN 9789897583544. doi: 10.5220/0007372800770088.
Abstract: Scene graphs, as found in many visualization systems are a well-established concept for modeling virtual scenes in computer graphics. State-of-the-art approaches typically issue appropriate draw commands while traversing the graph. Equipped with a functional programming mindset we take a different approach and utilize attribute grammars as a central concept for modeling the problem domain declaratively. Instead of issuing draw commands imperatively, we synthesize first class objects describing appropriate draw commands. In order to make this approach practical in the face of dynamic changes to the scene graph, we utilize incremental evaluation, and thereby avoid repeated evaluation of unchanged parts. Our application prototypically demonstrates how complex systems benefit from domain-specific languages, declarative problem solving and the implications thereof. Besides from being concise and expressive, our solution demonstrates a real-world use case of self-adjusting computation which elegantly extends scene graphs with well-defined reactive semantics and efficient, incremental execution.
URL http://dx.doi.org/10.5220/0007372800770088.
Markus Tavenrath. Handling massive transform updates in a scenegraph, mar 2016. URL http://on-demand.gputechconf.com/gtc/2016/presentation/s6131-tavenrath-scenegraph.pdf.
Robert F Tobler. Separating semantics from rendering: a scene graph based architecture for graphics applications. The Visual Computer, 27(6-8):687–695, 2011. doi: 10.1007/s00371-011-0572-0.
Abstract: A large number of rendering and graphics applications developed in research and industry are based on scene graphs. Traditionally, scene graphs encapsulate the hierarchical structure of a complete 3D scene, and combine both semantic and rendering aspects. In this paper, we propose a clean separation of the semantic and rendering parts of the scene graph. This leads to a generally applicable architecture for graphics applications that is loosely based on the well-known Model-View-Controller (MVC) design pattern for separating the user interface and computation parts of an application. We explore the benefits of this new design for various rendering and modeling tasks, such as rendering dynamic scenes, out-of-core rendering of large scenes, generation of geometry for trees and vegetation, and multi-view rendering. Finally, we show some of the implementation details that have been solved in the process of using this software architecture in a large framework for rapid development of visualization and rendering applications.
URL http://dx.doi.org/10.1007/s00371-011-0572-0.
Michael Wörister, Harald Steinlechner, Stefan Maierhofer, and Robert F Tobler. Lazy incremental computation for efficient scene graph rendering. In Proceedings of the 5th high-performance graphics conference, pages 53–62. ACM, 2013. doi: 10.1145/2492045.2492051.
Abstract: In order to provide a highly performant rendering system while maintaining a scene graph structure with a high level of abstraction, we introduce improved rendering caches, that can be updated incrementally without any scene graph traversal. The basis of this novel system is the use of a dependency graph, that can be synthesized from the scene graph and links all sources of changes to the affected parts of rendering caches. By using and extending concepts from incremental computation we minimize the computational overhead for performing the necessary updates due to changes in any inputs. This makes it possible to provide a high-level semantic scene graph, while retaining the opportunity to apply a number of known optimizations to the rendering caches even for dynamic scenes. Our evaluation shows that the resulting rendering system is highly competitive and provides good rendering performance for scenes ranging from completely static geometry all the way to completely dynamic geometry.
URL http://dx.doi.org/10.1145/2492045.2492051.
Bob Zeleznik, Loring Holden, Michael Capps, Howard Abrams, and Tim Miller. Scene-graph-as-bus: Collaboration between heterogeneous stand-alone 3-d graphical applications. In Computer Graphics Forum, volume 19, pages 91–98. Wiley Online Library, 2000. doi: 10.1111/1467-8659.00401.
Abstract: We describe the Scene-Graph-As-Bus technique (SGAB), the first step in a staircase of solutions for sharing software components for virtual environments. The goals of SGAB are to allow, with minimal effort, independently-designed applications to share component functionality; and for multiple users to share applications designed for single users.This paper reports on the SGAB design for transparently conjoining different applications by unifying the state information contained in their scene graphs. SGAB monitors and maps changes in the local scene graph of one application to a neutral scene graph representation (NSG), distributes the NSG changes over the network to remote peer applications, and then maps the NSG changes to the local scene graph of the remote application. The fundamental contribution of SGAB is that both the local and remote applications can be completely unaware of each other; that is, both applications can interoperate without code or binary modification despite each having no knowledge of networking or interoperability.